Si vous êtes à la recherche d'une formation elearning en statistique appliquée, que vous soyez statisticienne ou statisticien de base ou non, vous êtes au bon endroit. Dans cette formation MOOC, je démystifie les statistiques en ligne, avec une couche importante de pratique sous R.
MOOC en ligne gratuit : avancez à votre rythme
Approche intuitive et conceptuelle
Pas de recours à des formules mathématiques complexes
+8h de vidéos + supports PDF + scripts R réutilisables
De la statistique descriptive aux modèles (tests, ACP, régression, ANOVA…)
Pour débutants à intermédiaires
Six minutes pour introduire les statistiques descriptives univariées, les statistiques descriptives bivariées, les tests statistiques, les statistiques exploratoires multivariées, la segmentation, la modélisation statistique et le Machine Learning supervisé.
Cette formation s'adresse à des utilisateurs des statistiques, novices ou avancés, chercheurs, ingénieurs, techniciens, doctorants, des secteurs privé ou académique.
Le contenu est conçu de manière à être compris par des personnes provenant de toute discipline : biostatistique, recherche clinique, analyse sensorielle, sciences sociales, agronomie, écologie, marketing, finance, etc.
À l’issue de cette formation en statistiques avec R, vous aurez acquis les bases essentielles en statistique appliquée et serez capable d’analyser vos propres données de manière autonome.
Vous saurez mettre en œuvre les principales méthodes statistiques sous R, interpréter les résultats et les mobiliser pour répondre à des problématiques concrètes issues de votre domaine d'expertise.
Cette formation ne propose pas :
Le détail mathématique poussé du fonctionnement des outils. Nous privilégions l'approche conceptuelle et intuitive.
Un cours avancé de programmation sous R. Nous proposons uniquement une introduction à l'utilisation élémentaire de R. Cependant, cette initiation sera suffisamment complète pour vous permettre de mettre en application les notions de statistique développées tout au long de la formation.
Cette formation vous permet de maîtriser progressivement les principales méthodes d’analyse statistique avec R. Suivez-la à votre rythme. Vous pourrez bientôt faire parler vos données.
Commençons par le commencement : voici une vidéo-éclair d'introduction aux statistiques.
Vous avez un jeu de données sous les yeux. Un jeu de données surréaliste, avec des extraterrestres, en l'occurrence. Quelles questions peut-on se poser pour en tirer des informations alléchantes ?
R est le logiciel de statistique open-source le plus puissant. Il fonctionne avec des lignes de commande que l'utilisateur organise en scripts. Il offre des possibilités considérables de calcul statistique et d'automatisation.
Cette section présente une série de vidéos vous permettant de prendre en main rapidement le logiciel pour une utilisation de base, nécessaire pour la suite de la formation.

Que sont les statistiques ? Définitions de concepts clés (variables quantitatives et qualitatives, individu, échantillon, population, etc.)

Premiers pas en statistiques : comment décrire chaque colonne à part dans un jeu de données ?
Cette approche permet :
D'avoir une première caractérisation des données
De détecter des extrêmes ou des données aberrantes et de les corriger assez tôt dans le processus d'analyse
D'inspirer la suite de l'analyse, quelquefois :)
Nous verrons deux cas de figure : comment décrire une variable qualitative et comment décrire une variable quantitative.

Comment décrire le lien entre deux variables ? Le rendement est-il lié au fertilisant appliqué ? L'âge est-il lié à la pression systolique des patients ? La préférence du produit A est-elle liée à l'origine du consommateur ?
Nous exploiterons méthodiquement plusieurs outils couramment utilisés en statistiques descriptives bivariées : tableau de contingence, nuage de points, coefficients de corrélation, box-plots groupés, etc.

Comment évaluer la significativité statistique d'une différence ou d'une relation ?
Dans cette partie nous examinerons différents aspects des tests statistiques : hypothèses nulle et alternative, seuil de risque et p-value.
Nous exécuterons plusieurs tests statistiques courants, exemples à l'appui : test t de Student, test du khi², tests de corrélation.

Les statistiques exploratoires multivariées permettent d'explorer efficacement des tableaux de données volumineux. Selon le type de données en entrée, différentes techniques existent.
Plusieurs méthodes reposent sur le principe de réduction de la dimensionnalité.
Comment répartir différents objets en groupes d'objets qui se ressemblent, statistiquement ? Par exemple, comment classer différents vins en groupes de vins similaires selon le profil sensoriel ? Comment classer différents patients selon leur génôme ? Comment classer des consommateurs selon leurs profils de préférences ?
Les techniques de classification ou clustering permettent de répondre à ces questions.

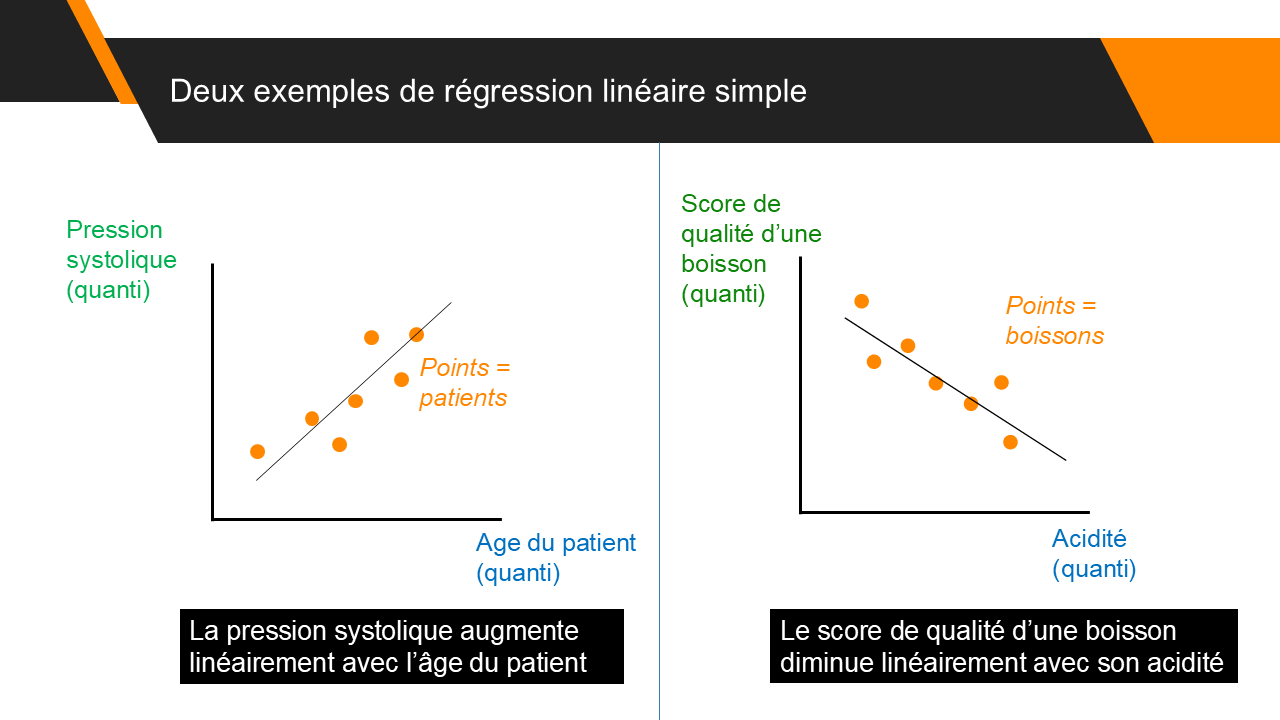
Comment expliquer une variable en fonction d'une ou plusieurs autres variables ?
Le score de qualité d’une boisson peut-il être expliqué par son acidité ?
La pression systolique est-elle affectée par l’âge du patient ? Par son Indice de Masse Corporelle ?
Le rendement agricole d’un champ dépend-il du type de fertilisant utilisé ? Du régime d’irrigation ?
Le risque de réaction allergique à un médicament est-il influencé par son dosage ?
Le montant de la rémunération affecte-t-il le risque de démission ?
Toutes ces questions peuvent être abordées via la modélisation statistique. Après une introduction à la notion de modélisation, nous aborderons un premier modèle statistique : la régression linéaire. Nous parlerons d'implémentation, d'interprétation et de mises en garde.
La régression logistique est un modèle statistique qui permet d'expliquer une variable qualitative en fonction d'une ou plusieurs variables explicatives.
Souvent, on prend en compte des variables à expliquer à deux modalités (binaires).
Exemples :
Le statut du patient (sain ou malade) peut-il être expliqué par tel ou tel facteur de risque ?
La présence d'une espèce protégée de lézard peut-il être expliqué par des variables environnementales ?

Comment expliquer une variable quantitative en fonction d'une ou plusieurs variables qualitatives ?
L'Analyse de Variance ou ANOVA est un modèle statistique qui permet d'aborder cette question.
Dans le cadre de l'ANOVA, les variables explicatives sont appelées facteurs.
Techniquement, l'ANOVA aide à comparer des moyennes issues de plusieurs groupes d'observations. Exemples de questions abordées :
Le type de fertilisant appliqué (N, P, K ou contrôle) induit-il une différence significative de rendement moyen d'un champ ? Il s'agit d'une problématique d'ANOVA à un facteur.
La pression systolique moyenne est-elle influencée par l'exposition fréquente au tabac (oui ou non) ? Par le sexe du patient ? Par l'interaction exposition-sexe ? Il s'agit d'une problématique d'ANOVA à deux facteurs.

Cette formation en ligne en statistiques avec R est conçue pour s’adapter à votre emploi du temps et à votre niveau. Vous avancez à votre rythme, sans contrainte de calendrier, et pouvez revenir autant que nécessaire sur les notions clés.
La formation combine :
Des vidéos pédagogiques,
Des supports écrits (PDF),
Des scripts R commentés et réutilisables, afin de vous permettre de pratiquer directement sur vos propres données.
Oui. La formation est conçue pour des débutants en statistique ou en analyse de données, ainsi que pour des profils ayant déjà quelques bases mais souhaitant consolider leurs acquis.
Les notions sont introduites progressivement, avec une approche pédagogique orientée compréhension et mise en pratique sous R.
Aucun prérequis n’est nécessaire.
La formation part des fondamentaux en statistique et introduit progressivement l’utilisation de R, sans supposer de compétences préalables en programmation. Une familiarité basique avec l’informatique est suffisante.
Vous apprendrez à analyser des données avec R, depuis les statistiques descriptives jusqu’à des méthodes plus avancées (tests statistiques, ACP, classifications, régressions, ANOVA).
L’accent est mis sur l'explication intuitive des outils, l’interprétation des résultats et l’application des méthodes à des données réelles.
La formation est 100 % préenregistrée, en accès libre en ligne. Avancez donc au rythme qui vous convient.
Les box plots ou boîtes à moustaches permettent de décrire efficacement une variable quantitative. Ils représentent des mesures robustes de la tendance centrale et de la dispersion. Ils permettent par ailleurs de détecter des données extrêmes.
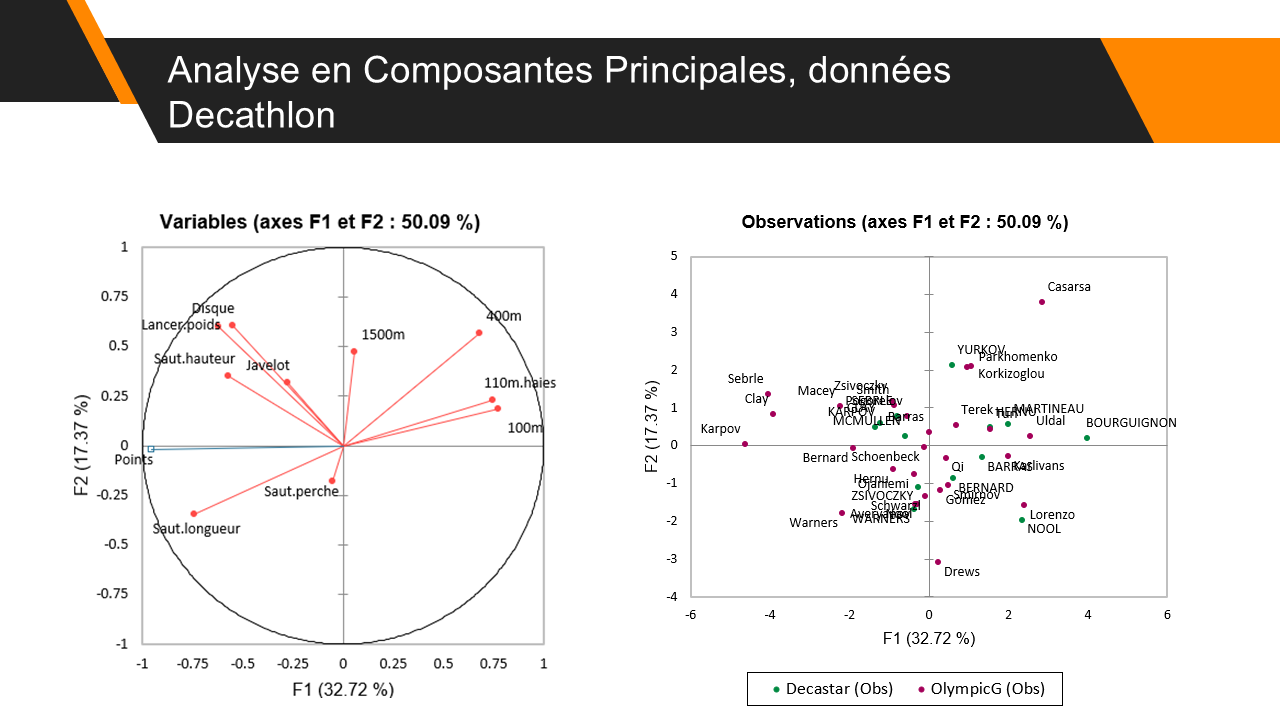
L'Analyse en Composantes Principales ou ACP permet d'explorer un tableau de variables quantitatives volumineux sur quelques graphiques compacts.
La régression logistique est un modèle statistique qui permet d'expliquer une variable qualitative en fonction d'un ensemble de variables explicatives.
L'Analyse de Variance ou ANOVA est un modèle statistique qui permet d'expliquer une variable quantitative en fonction d'une ou plusieurs variables qualitatives appelées facteurs.
Statistiques avec R - Livre gratuit (Vincent Isoz)
Stat' Apprendra - chaîne YouTube (Nancy Rebout)