- 16 avr.
10 modèles statistiques couramment utilisés en écologie pour relier une espèce à son environnement
- Jean Paul Maalouf
- 0 comments
En écologie, une question revient sans cesse : pourquoi telle espèce est-elle abondante ici, et absente là ? Une grenouille prolifère dans certaines mares et disparaît des mares voisines, parfois pour des raisons difficiles à saisir à l'œil nu. Pour y répondre rigoureusement, les écologues modélisent le lien entre la présence ou l'abondance d'une espèce et les facteurs environnementaux qui l'entourent — température, ressource trophique, salinité, présence d'un prédateur ou d'un compétiteur.
Cette démarche sous-entend en général l’un (ou plusieurs) des objectifs suivants :
Mieux cerner la niche écologique d’une espèce
Identifier les facteurs limitants ou favorables
Construire des cartes de répartition, dans l’état actuel ou dans des scénarios futurs (changement climatique, aménagement, etc.)
Mais une difficulté apparaît rapidement :
👉 il n’existe pas un seul modèle statistique adapté à toutes les situations.
Le choix du modèle dépend :
du type de variable réponse (présence/absence, abondance, communauté…)
de la structure des données (répétitions, spatialisation…)
et des hypothèses écologiques sous-jacentes
Voici 10 modèles statistiques couramment utilisés en écologie, avec leurs cas d’usage typiques.
Photo : Susanne Jutzeler
Voir aussi 10 outils d'analyse multivariée couramment utilisés en écologie.
1. Modèle linéaire
Réponse : quantitative, gaussienne
Exemple : biomasse d'une plante présente dans tous les relevés (peu ou pas de zéros)
Principe : on assume une relation linéaire entre les facteurs environnementaux et l'abondance. C'est le modèle le plus simple et le plus facile à interpréter. Attention, ce modèle est rarement adapté aux données écologiques, qui engendrent des résidus non-gaussiens.
Fonctions R :
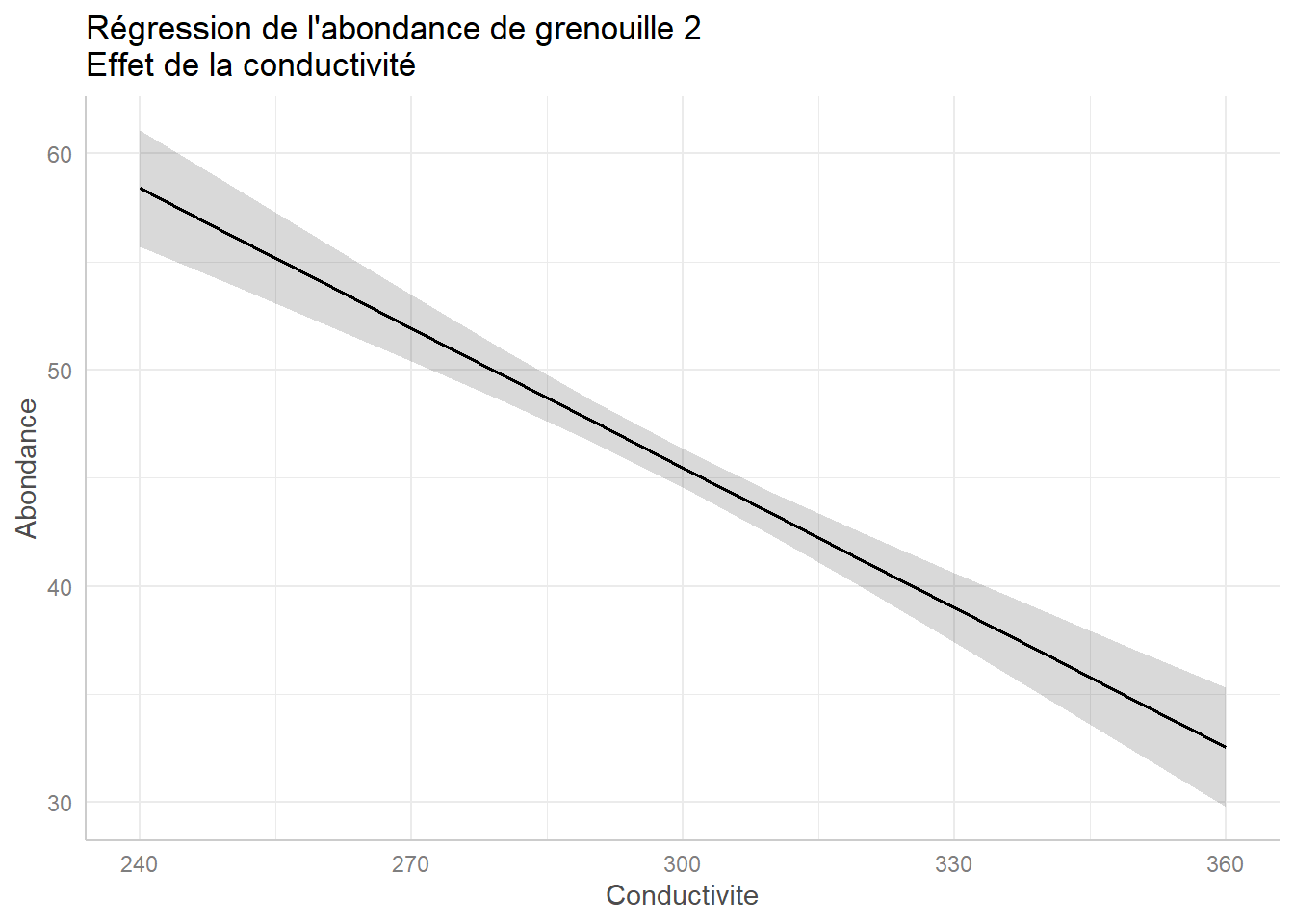
lm(biomasse ~ facteur1 + facteur2…)Figure : régression linéaire de l'abondance d'une espèce de grenouille en fonction de la conductivité. La relation est linéaire.
2. Modèle linéaire généralisé binaire (GLM logistique)
Réponse : présence ou absence d'une espèce (0/1)
Exemple : la grenouille est-elle présente dans ce relevé ?
Principe : on modélise la probabilité de présence via une fonction logit. On assume des liens linéaires entre les facteurs environnementaux et le log-odds de présence. En cas de surdispersion, on peut recourir au modèle quasi-binomial.
Fonctions R :
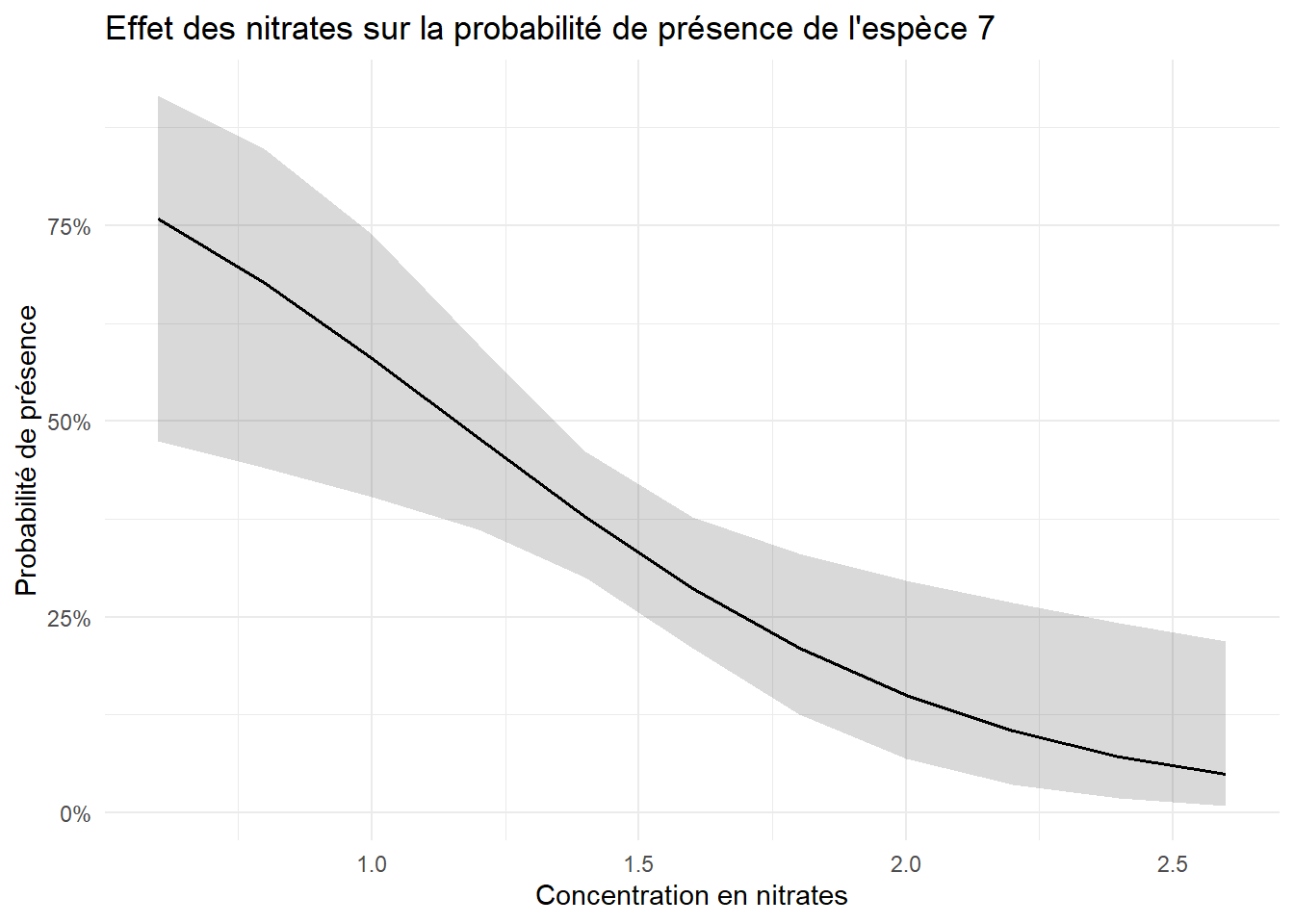
glm(presence ~ facteur1 + facteur2…, family = "binomial")/glm(family = "quasibinomial")Figure : régression logistique de la présence ou l'absence d'une espèce de grenouille en fonction de la concentration en nitrates. La courbe typique de forme sigmoïde représente une probabilité de présence.
3. GAM (Generalized Additive Model)
Réponse : quantitative gaussienne, comptage ou binaire selon le contexte
Exemple : relation non-linéaire entre la température de l'eau et la biomasse ou l'abondance d'une grenouille
Principe : le GAM remplace les effets linéaires par des splines (fonctions lissées), ce qui permet de capturer des relations complexes sans avoir à en spécifier la forme à l'avance. Particulièrement utile lorsque la réponse présente un optimum (relation en cloche), fréquent en écologie.
Fonctions R :
mgcv::gam(abondance ~ s(facteur1) + s(facteur2)…)— avecfamily = "poisson"ou"binomial"selon la nature de la réponse-
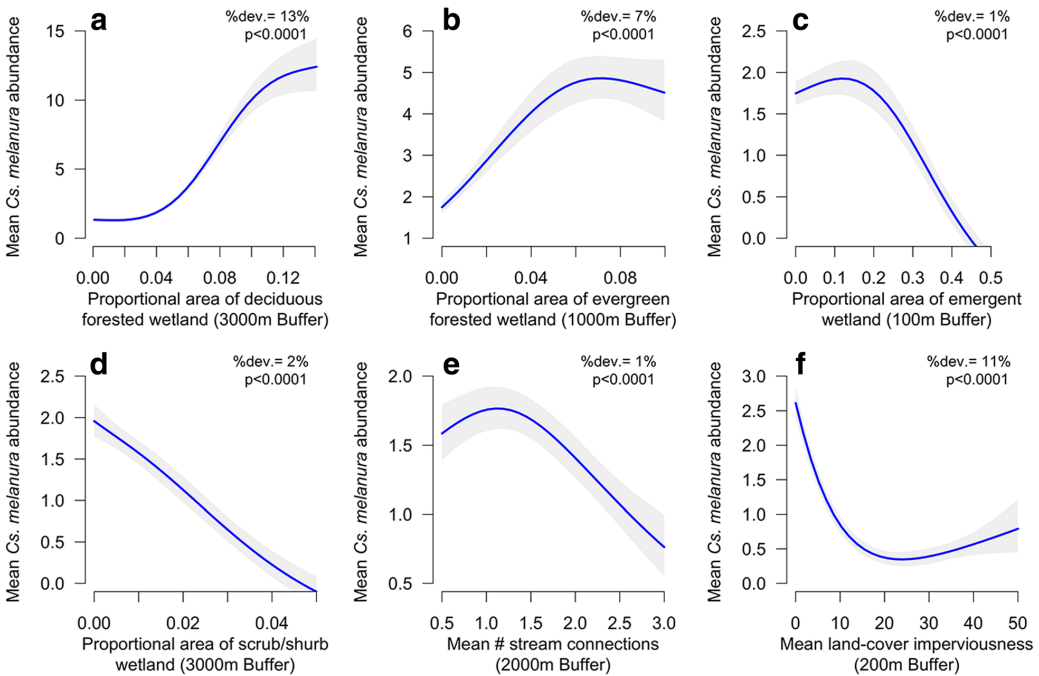
Figure : modélisation GAM de l'abondance de Culiseta melanura en fonction de différentes variables environnementales, d'après Skaff et al. (2017).
4. Modèles de Poisson et quasiPoisson
Réponse : comptages (nombres entiers ≥ 0)
Exemple : nombre de grenouilles détectées dans un point d'écoute
Principe : le modèle de Poisson est le point de départ naturel pour des données de comptage. Si la variance est supérieure à la moyenne (surdispersion — fréquent en écologie !), le modèle quasiPoisson ou le modèle binomial négatif sont préférables.
Fonctions R :
glm(abondance ~ facteur1 + facteur2…, family = "poisson")/glm(family = "quasipoisson")/MASS::glm.nb(binomial négatif)
5. Modèles zero-inflated (et hurdle)
Réponse : comptages avec excès de zéros
Exemple : la grenouille est absente de nombreux sites (zéros structurels) mais parfois très abondante là où elle est présente
Principe : en écologie, les jeux de données contiennent souvent bien plus de zéros que ce qu'un modèle de Poisson ou binomial négatif prédit. Le modèle zero-inflated mélange un processus binaire (présence/absence) et un processus de comptage. Le modèle hurdle (à barrière) traite les zéros et les valeurs positives séparément — une façon élégante de modéliser « est-ce que l'espèce s'installe ? » et « combien d'individus sont présents ? » comme deux questions distinctes.
Fonctions R :
pscl::zeroinfl(…)/pscl::hurdle(…)/glmmTMB::glmmTMB(family = poisson ou nbinom1)
6. Modèles pour communautés (CCA / RDA)
Réponse : matrice sites × espèces (ou dates × espèces)
Exemple : comment la température, la profondeur ou le pH structurent-ils l'ensemble de la communauté planctonique ?
Principe : plutôt que de modéliser une espèce à la fois, on analyse simultanément la composition en espèces. La RDA (Analyse de Redondance) suppose des réponses linéaires ; la CCA (Analyse Canonique des Correspondances) suppose des réponses unimodales, plus réalistes pour des gradients écologiques longs. Ces méthodes produisent des représentations graphiques (biplots) qui donnent une vision synthétique des relations espèces-environnement.
Fonctions R :
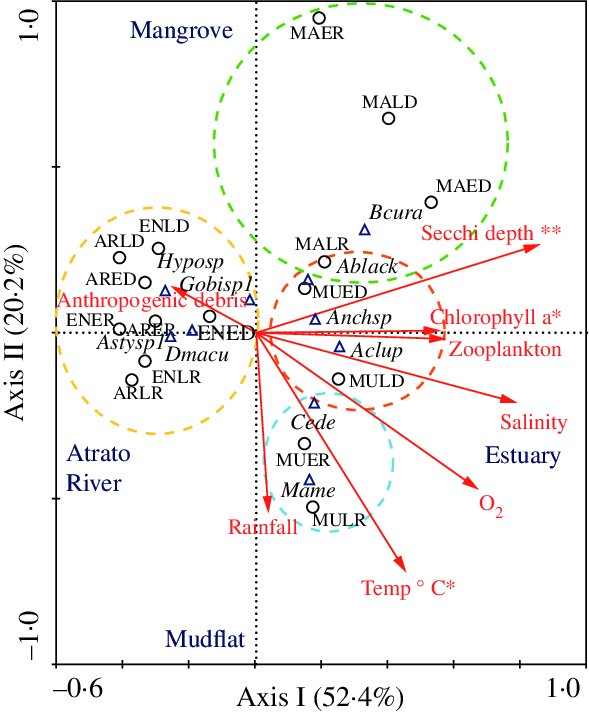
vegan::rda(matrice_espèces ~ facteur1 + facteur2…)/vegan::cca(…)Figure : Graphique d'Analyse Canonique des Correspondances pour expliquer la communauté de poissons au stade larvaire (triangles) en fonction de facteurs environnementaux (flèches rouges) prélevés sur différents sites (cercles) dans le delta d'une rivière en Colombie, d'après Correa-Herrera et al. (2017).
7. Modèles mixtes
Réponse : toute variable réponse (gaussienne, comptage, binaire…)
Exemple : des grenouilles sont mesurées dans plusieurs mares, elles-mêmes réparties dans plusieurs bassins versants.
Principe : les modèles mixtes intègrent des effets aléatoires (mare, bassin, année…) qui capturent la non-indépendance des observations. Ceci permet ainsi d'éviter la pseudoréplication. Chaque type de modèle classique (LM, GLM, GAM) a son pendant mixte.
Fonctions R :
lme4::lmer(gaussien) /lme4::glmer(family = "binomial" ou "poisson")/mgcv::gamm/glmmTMB::glmmTMB-
Figure : plan d'échantillonnage de l'abondance d'une espèce de grenouilles. Il existe une corrélation potentielle entre les observations issues de la même mare, et une autre corrélation potentielle entre les observations issues du même bassin versant.
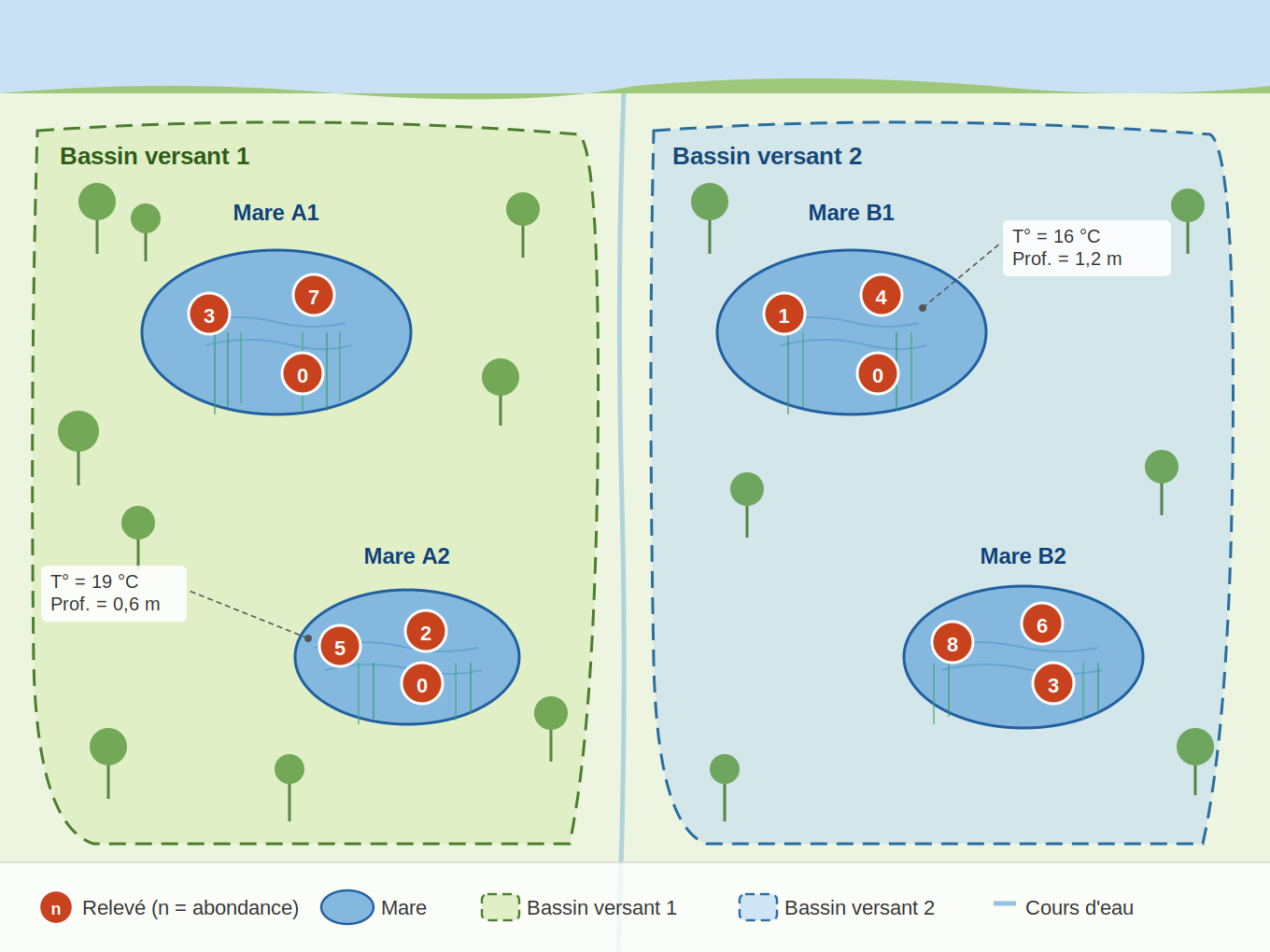
8. GLS et modèles avec autocorrélation spatiale
Réponse : variable quantitative ou comptage collecté en contexte géographique
Exemple : abondance de grenouilles mesurée sur un réseau de stations — deux stations proches tendent à se ressembler davantage, ce qui entraîne une violation de l'hypothèse d'indépendance
Principe : le GLS (Generalized Least Squares) modélise explicitement la structure de covariance des résidus. Pour des données géographiques, on utilise en général un noyau de Matérn qui décrit la manière dont la corrélation décroît avec la distance. Ignorer l'autocorrélation spatiale conduit à sous-estimer les intervalles de confiance et à produire des tests invalides — une erreur fréquente dans la littérature.
Fonctions R :
nlme::gls(…, correlation = corSpatial)/spaMM::fitme(… + Matern(1 | lat + lon))
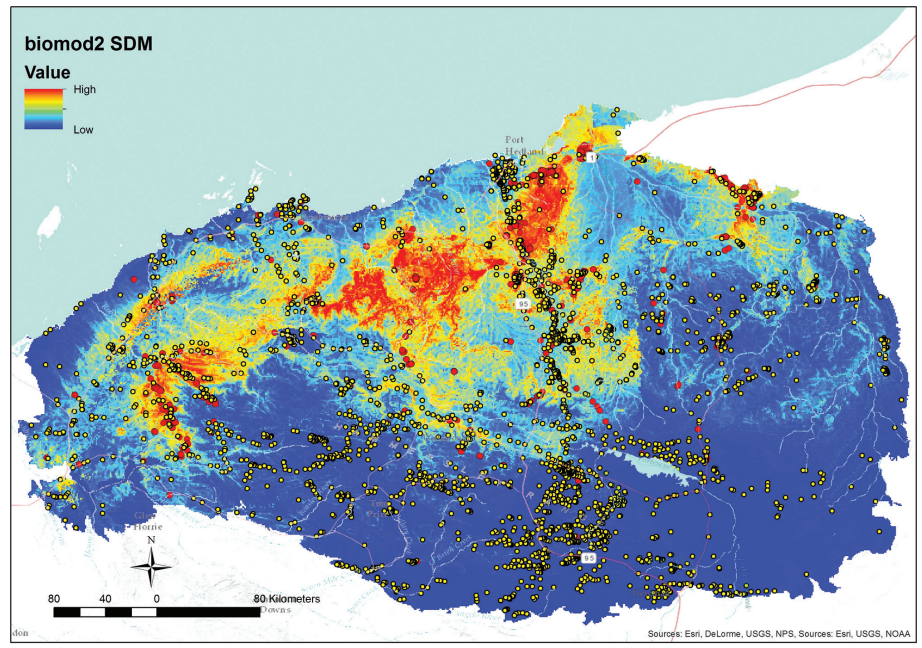
9. SDM (Species Distribution Model)
Réponse : présence/absence ou abondance dans l'espace géographique
Exemple : prédire la répartition actuelle de la grenouille rousse sur la France, ou projeter cette répartition sous différents scénarios de changement climatique (+2 °C, +4 °C)
Principe : les SDM mettent en relation des observations géoréférencées avec des couches environnementales (température, précipitations, occupation du sol…) pour construire une carte de l'habitat potentiel. Ils reposent souvent sur des modèles statistiques classiques (GLM, GAM) ou propres au Machine Learning supervisé (Random Forests, Boosting, réseaux de neurones...). Une de leurs forces est leur capacité à produire des cartes prédictives.
Outils courants :
biomod2,sdm,terra+ MaxEnt, ou des pipelines combinanttidysdmettidymodelsFigure : projection de l'abondance de Dasyurus hallucatus selon un modèle d'ensemble produit par biomod2, d'après Molloy et al. (2017)
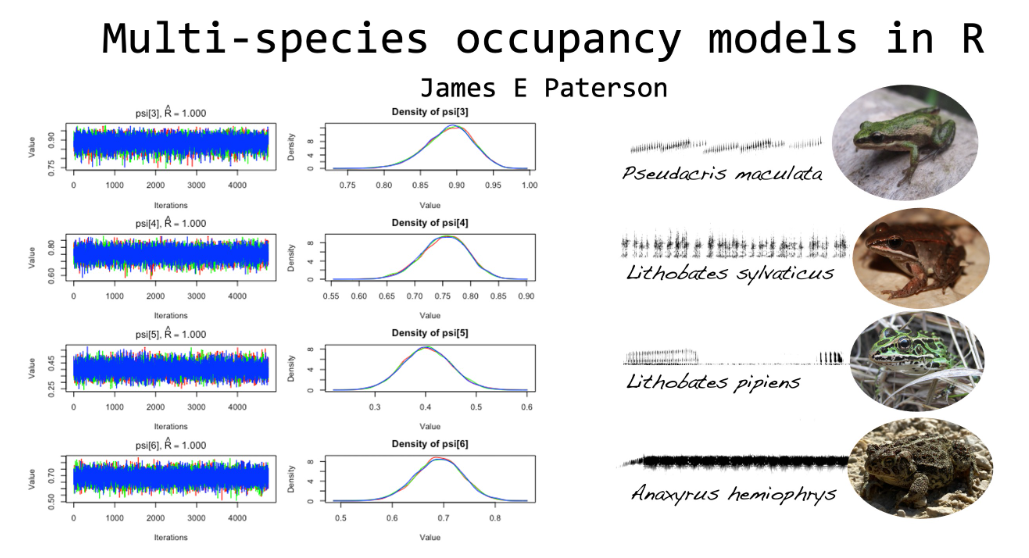
10. Inférence bayésienne
Réponse : toute variable réponse, mais particulièrement utile pour des modèles complexes à plusieurs niveaux
Exemple : modèle d'occupation qui tient compte de la détectabilité imparfaite de la grenouille (un individu présent n'est pas systématiquement observé), ou intégration de connaissances a priori issues de la littérature.
Principe : au lieu d'estimer un seul jeu de paramètres (maximum de vraisemblance), l'inférence bayésienne produit une distribution de probabilité sur chaque paramètre (distribution postérieure). Cela permet d'intégrer des connaissances préalables via des distributions a priori, de propager l'incertitude de façon cohérente, et de construire des modèles hiérarchiques très élaborés. La contrepartie est une mise en œuvre plus complexe et un temps de calcul parfois élevé.
Fonctions R :
brms::brm(…)(interface formule similaire à lme4),rstan,nimble,JAGSFigure : première page d'un tutoriel développé par James E Paterson, qui met en place un modèle dans un cadre bayésien, pour évaluer la probabilité d'occupation de plusieurs espèces dans une communauté en prenant en compte une probabilité de détection.
Conclusion : comment choisir son modèle ?
Il n'existe pas de modèle universel — dans un premier temps, il est utile de se poser trois questions simples :
Quelle est la nature de ma variable réponse ? Binaire, comptage, abondance continue, composition d'une communauté ?
Quelle est la structure de mes données ? Observations groupées, données géoréférencées, excès de zéros ?
Quel est mon objectif ? Comprendre les mécanismes, prédire dans l'espace ou dans le temps, tester une hypothèse ?
En pratique, la démarche consiste souvent à commencer par le modèle le plus simple adapté à la réponse (LM, GLM), vérifier les résidus, et complexifier si nécessaire (ajout d'effets aléatoires, passage à un GAM, gestion de l'autocorrélation spatiale…). La parcimonie reste une vertu en modélisation écologique.
Enfin, aucun modèle ne vaut mieux que les données qui l'alimentent. Un plan d'échantillonnage bien conçu — qui minimise les biais de détection, couvre les gradients environnementaux et réplique correctement les traitements — reste le fondement de toute analyse robuste.
Pour aller plus loin, voici 10 outils d'analyse multivariée couramment utilisés en écologie.
Besoin d'un accompagnement ou d'une formation en statistique pour l'analyse de vos données en écologie ?
- Gratuit
Formez-vous aux statistiques avec R
- Cours
- 80 Leçons